Карпова И.П.
ОПТИМИЗАЦИЯ РЕЛЯЦИОННЫХ ЗАПРОСОВ
Материалы к лекциям по курсу "Базы данных"
В оптимизацию реляционных запросов входят два различных аспекта. Во-первых, это внутренняя задача СУБД, которая заключается в определении наиболее оптимального (эффективного) способа выполнения реляционных запросов. Во-вторых, это задача программиста (или квалифицированного пользователя): она заключается в написании таких реляционных запросов, для которых СУБД могла бы использовать более эффективные способы нахождения данных. Сначала рассмотрим первый аспект.
Обработка запроса в реляционных СУБД
Каждая команда языка манипулирования данными может быть выполнена разными способами. Определение наиболее оптимального плана выполнения запроса называется оптимизацией. Выбором этого плана занимается оптимизатор – специальная компонента СУБД.
Выполнение запроса состоит из последовательности шагов, каждый из которых либо физически извлекает данные из памяти, либо делает подготовительную работу. Последовательность шагов, которую строит оптимизатор, называется планом выполнения.
Обработка запроса, поступившего в систему и представленного на некотором языке запросов, состоит из этапов или фаз, представленных на рис.1.
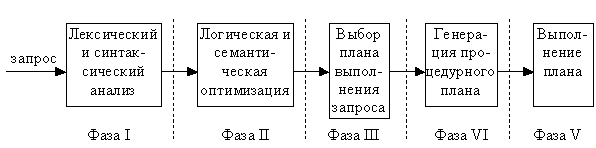
Рис.1. Последовательность выполнения запросов в реляционных СУБД
На первой фазе запрос, представленный на языке запросов, подвергается лексическому и синтаксическому анализу. При этом вырабатывается его внутреннее представление, отражающее структуру запроса и содержащее информацию, которая характеризует объекты базы данных, упомянутые в запросе (отношения, поля и константы). Информация о хранимых в базе данных объектах выбирается из каталогов базы данных (словаря-справочника данных). Внутреннее представление запроса используется и преобразуется на следующих стадиях обработки запроса.
На второй фазе запрос в своем внутреннем представлении подвергается логической оптимизации. При этом могут применяться различные преобразования, "улучшающие" начальное представление запроса. Среди этих преобразований могут быть эквивалентные преобразования, после проведения которых получается внутреннее представление, семантически эквивалентное начальному (например, приведение запроса к некоторой канонической форме). Преобразования могут быть и семантическими, когда получаемое представление не является семантически эквивалентным начальному, но гарантируется, что результат выполнения преобразованного запроса совпадает с результатом запроса в начальной форме при соблюдении ограничений целостности, существующих в базе данных. В любом случае после выполнения второй фазы обработки запроса его внутреннее представление остается непроцедурным, хотя и является в некотором смысле более эффективным, чем начальное.
Третий этап обработки запроса состоит в выборе на основе информации, которой располагает оптимизатор, набора альтернативных процедурных планов выполнения данного запроса в соответствии с его внутреннем представлением, полученным на второй фазе. Основой является информация о существующих путях доступа к данным. Единственный путь доступа, который возможен в любом случае, – это последовательное чтение (FULL). Возможность использования других путей доступа зависит от способов размещения данных в памяти (например, кластеризация данных), наличия индексов и формулировки самого запроса.
На этом же этапе для каждого плана оценивается предполагаемая стоимость выполнения запроса по этому плану. При оценках используется либо доступная оптимизатору статистическая информация о состоянии базы данных, либо информация о механизмах реализации различных путей доступа. Из полученных альтернативных планов выбирается наиболее оптимальный с точки зрения некоторого (заранее выбранного или заданного) критерия. Внутреннее представление этого плана теперь соответствует обрабатываемому запросу.
На четвертом этапе по внутреннему представлению наиболее оптимального плана выполнения запроса формируется процедурное представление плана. Выполняемое представление плана может быть программой в машинных кодах, если, как в случае System R, система ориентирована на компиляцию запросов в машинные коды, или быть машинно-независимым, но более удобным для интерпретации, если, как в случае INGRES, система ориентирована на интерпретацию запросов. В нашем случае это непринципиально, поскольку четвертая фаза обработки запроса уже не связана с оптимизацией.
Наконец, на последнем, пятом этапе обработки запроса происходит его реальное выполнение в соответствии с выполняемым планом запроса. Это либо выполнение соответствующей подпрограммы, либо вызов интерпретатора с передачей ему для интерпретации выполняемого плана.
Существуют два принципиально разных подхода к оптимизации запросов. Если оптимизатор использует информацию о механизмах реализации путей доступа, то метод оптимизации основан на синтаксисе (на правилах). Если же основой является статистическая информация о распределении данных, то это метод оптимизации, основанный на стоимости (на издержках). Рассмотрим их подробнее.
Метод оптимизации, основанный на синтаксисе
При использовании этого метода план составляется на основании существующих путей доступа и их рангов. Ранжирование путей доступа выполняется на основании знаний о правилах и последовательности осуществления этих путей. В табл.1 в качестве примера приведены ранги путей доступа для СУБД Oracle.
Табл.1. Ранг путей доступа для СУБД Oracle
|
Ранг |
Пути доступа |
|
1 |
Одна строка по ROWID* |
|
2 |
Одна строка по кластерному соединению |
|
3 |
Одна строка по хеш-кластеру с уникальным или первичным ключом |
|
4 |
Одна строка по уникальному или первичному ключу |
|
5 |
Кластерное соединение |
|
6 |
Ключ хеш-кластера |
|
7 |
Ключ индексного кластера |
|
8 |
Составной индекс |
|
9 |
Индекс по одиночному столбцу |
|
10 |
Индексный поиск по закрытому интервалу |
|
11 |
Индексный поиск по открытому интервалу |
|
12 |
Сортировка-объединение |
|
13 |
MAX и MIN по индексированному столбцу |
|
14 |
ORDER BY по индексированному столбцу |
|
15 |
Полный просмотр таблицы |
* – идентификатор строки – значение, которое может быть однозначно преобразовано в физический адрес записи
Ранг пути доступа определяется на основании знаний о последовательности реализации этого пути. Например, одна строка по хеш-кластеру с уникальным или первичным ключом (ранг 3) будет выбираться в среднем быстрее, чем одна строка по уникальному или первичному ключу (ранг 4), потому что для получения ROWID строки из хеш-кластера достаточно применить к значению ключа хеш-функцию, а для получения ROWID по индексу требуется лишнее обращение к индексу (который может в данный момент отсутствовать в оперативной памяти, что вызовет обращение к диску).
Метод оптимизации, основанный на синтаксисе, учитывает иерархическое старшинство операций. Если для какой-либо операции существует более одного пути ее выполнения, то выбирается тот путь, чей ранг выше, т.к. в большинстве случаев он выполняется быстрее, чем путь с более низким рангом. План выполнения запроса формируется из выбранных путей доступа с максимальными рангами (рис. 2).
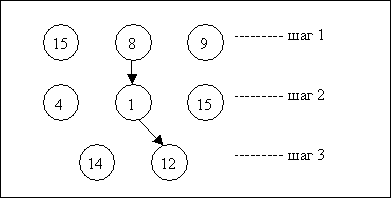
Рис.2. Построение плана выполнения запроса в методе оптимизации по синтаксису
Метод оптимизации, основанный на стоимости
При использовании этого метода оптимизатор сначала строит несколько возможных планов выполнения запроса. При этом он применяет некоторые эвристики, т.е. правила, полученные опытным путем. Эти правила позволяют сузить пространство поиска оптимального плана благодаря тому, что неэффективные планы отбрасываются в самом начале и не рассматриваются. Примером эвристики может послужить такое правило: хорошим является такой план, в котором селекция производится на раннем этапе выполнения запроса.
Для каждого из построенных планов рассчитывается его стоимость. Она определяется на основании статистики данных в таблицах, к которым обращается команда, и связанными с ними кластерами и индексами. Статистика касается распределения значений данных в таблице и может включать в себя количество записей в таблице, минимальные и максимальные значения данных по столбцам и другие параметры. Стоимость – это оценка ожидаемого времени выполнения запроса с использованием конкретного плана выполнения. Оптимизатор может учитывать количество необходимых ресурсов памяти, стоимость операций ввода-вывода, времени процессора и оперативной памяти, необходимой для выполнения плана.
Естественно, для сравнения планов выполнения оптимизатору нужен критерий. В качестве критерия оптимизации может выступать:
· Наилучшая общая производительность системы. Вообще говоря, её можно достичь, если из всех планов выбирать те, которые требуют меньше всего ресурсов (памяти и ЦП). Это позволит увеличить степень параллельности работы системы и повысить общую производительность, хотя при этом время выполнения отдельных запросов увеличится.
· Минимальное время реакции – время, необходимое для обработки первой строки. Этот критерий чаще применяется при работе в интерактивном режиме, но только для запросов, которые не содержат агрегирующих функций и не требуют сортировки данных результата.
· Минимальные затраты времени на обработку всех строк, к которым обращается данная команда. Этот критерий используется обычно при работе в пакетном режиме или когда невозможно выдавать результат по частям.
Из множества возможных планов выполнения запроса (обычно, 2-3 плана) оптимизатор в соответствии с критерием выбирает лучший план (рис. 3).
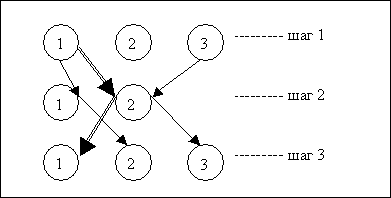
Рис.3. Построение плана выполнения запроса в методе оптимизации по стоимости
СУБД, использующие метод оптимизации по стоимости, могут учитывать распределение данных и характеристики хранения таблиц, распределение значений в столбце. Последняя характеристика может быть определена с помощью гистограмм. Все множество значений столбца упорядочивается и разбивается на N интервалов (рис.4). Гистограмма помогает определить равномерность или неравномерность распределения данных. Например, на рис.4,б представлено неравномерное распределение данных для некоторого столбца F. В словарь-справочник данных записываются полученные значения столбца (1,4,4,5,6,10,11,20,35,60,100). При анализе запроса, например, с условием (F<5) система сможет с помощью этой гистограммы определить, что через индекс ей придется выбрать не менее 15% записей таблицы.
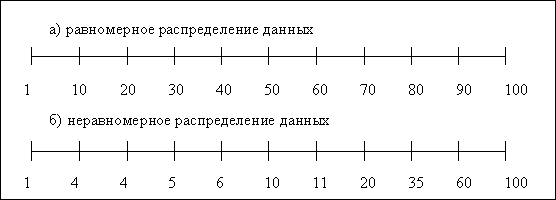
Рис.4. Примеры равномерного (а) и неравномерного (б) распределения значений
Существуют различные подходы к порядку сбора статистики. Некоторые СУБД постоянно собирают статистическую информацию, но это может уменьшит быстродействие системы. Другие позволяют осуществлять сбор статистики периодически, например, в период минимальной загрузки системы. Третьи предлагают администратору специальные средства для сбора статистики, которые запускаются интерактивно по его команде. В последнем случае в обязанность администратора (администратора данных или приложений) входит выбор таблиц для анализа и периодическое обновление статистики данных.
Гистограммы полезны только в тех случаях, когда они отражают актуальное распределение данных. Если распределение меняется, гистограмму нужно обновлять; если изменение данных не изменяет их распределения, то обновление гистограммы не требуется. Построение гистограммы бесполезно в следующих случаях:
· значения столбца распределены равномерно;
· столбец не используется в предикатах запросов;
· значения столбца уникальны и используются только в предикатах эквивалентности.
Порядок оптимизации выполнения запроса
Оптимизация выполнения запроса осуществляется в следующем порядке:
1. Вычисление выражений и условий, содержащих константы.
2. Преобразование сложной команды в эквивалентную ей с использованием соединения (проводится не всегда).
3. Если команда выполняется над представлением, то оптимизатор обычно объединяет запрос на создание представления и запрос к этому представлению в одну команду.
4. Выбор метода оптимизации.
5. Выбор путей доступа к таблицам, к которым обращается запрос.
6. Выбор порядка соединения (если в запросе соединяются несколько таблиц, то оптимизатор определяет, какие две таблицы будут соединяться первыми, какая таблица следующей будет подключаться в результату и т.д.).
7. Выбор операции соединения для каждой команды соединения.
Пример. Рассмотрим следующую команду SQL:
SELECT empNo FROM emp
WHERE eName = 'Tom' AND Sal > 2000;
Пусть таблица Emp имеет следующее правило целостности и индексы:
· столбец empNo определен как PRIMARY KEY, ему соответствует индекс PK_EMPNO;
· существует индекс ENAME_IND для столбца eName;
· существует индекс SAL_IND для столбца Sal.
Возможны следующие пути доступа:
· полный просмотр таблицы (ранг 15);
· доступ по одиночному индексу ENAME_IND. Этот путь становится доступным по условию eName = 'Tom' (ранг 9);
· доступ с помощью открытого интервала SAL>2000, используя индекс SAL_IND (ранг 11).
Индекс PK_EMPNO недоступен, т.к. не происходит обращение к полю empNo. Оптимизатор выберет доступ по одиночному индексу с рангом 9.
При выборе пути доступа в методе оптимизации по стоимости для оценки каждого плана выполнения оптимизатор использует статистику. (На выбор оптимизатора могут повлиять подсказки, заданные пользователем в команде).
Примеры.
1. Рассмотрим запрос, выбирающий сотрудников с номерами больше 7500:
SELECT * FROM Emp
WHERE empNo < 7500;
Статистика для столбца empNo, в частности, включает значения HIGH_VALUE и LOW_VALUE. Если нет гистограммы, то оптимизатор предполагает, что значения равномерно распределены в интервале [LOW_VALUE, HIGH_VALUE], и может определить процент значений, попадающий в интервал до 7500. Доступ будет осуществляться по индексу, если этот процент невысок (конкретное пороговое значение зависит и от других параметров, например, количества записей в блоке).
2. Рассмотрим запрос, выбирающий всех сотрудников-мужчин:
SELECT * FROM Emp
WHERE sex = 'м';
Оптимизатор предполагает, что значения 'м' и 'ж' равномерно распределены в таблице, т.е. приблизительно половина записей имеет значение 'м'. В этом случае оптимизатор выберет полный просмотр таблицы даже при наличии индекса по столбцу sex. Если есть гистограмма и распределение данных неравномерно, то оптимизатор может принять решение об использовании индекса.
Настройка приложений
Настройка команд SQL, которые используются в приложении, – это один из основных способов повышения производительности системы. Эта настройка должна производиться каждым разработчиком.
Для оптимизации приложений необходимо иметь представление о порядке и механизмах реализации запросов в СУБД. Основные информационные потоки между пользователями, оперативной памятью и базой данных приведены на рис. 5.
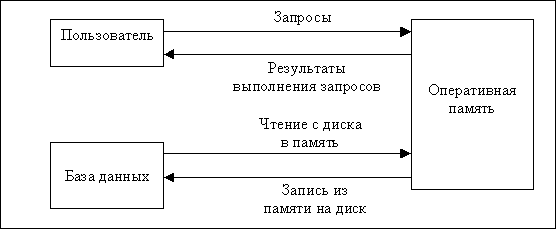
Рис.5. Информационные потоки в БД
В ОП хранятся все результаты ранее выполненных запросов до тех пор, пока эта память не потребуется для записи результатов последующих запросов.
Подготовленные к исполнению SQL-операторы обычно помещаются в разделяемую SQL-область. Перед началом выполнения запроса система проверяет, есть ли в этой области аналогичный запрос: если есть, то он отправляется на выполнение минуя стадию предварительной обработки (компиляции). Составляя запросы таким образом, чтобы они совпадали в уже имеющимися в SQL-области, можно исключить предобработку запроса, что является важным моментом оптимизации приложений.
Рекомендации по написанию запросов
1. Если запрос содержит несколько условий, то они должны располагаться в порядке уменьшения селективности. Например, при условии, что во втором отделе сотрудников около 5% от общего числа сотрудников предприятия, а женщин – примерно половина, запрос должен выглядеть так:
select * from emp
where deptNo=2 and sex='ж';
2. В запросе, который реализует соединение двух и более таблиц, эти таблицы должны стоять в списке в порядке уменьшения количества записей в них. Например, список пациентов по отделениям.
select * from patients p, depart d
where p.deptNo=d.id;
Графически это можно изобразить так:
|
|
|
|
|||||
3. Если запрос содержит условие типа (field LIKE '%…') или (field LIKE '_…'), то необходимо дополнять это условие так, чтобы система могла воспользоваться индексом по полю field (если он существует). Например, список всех хирургов:
select * from doctors
where special>'A' and special like '%хирург%';
4. Если запрос содержит условие для проиндексированного поля маленькой таблицы, которая может быть считана за одно обращение к памяти, то запрос нужно сформулировать так, чтобы система игнорировала индекс. Например, запрос на выборку названия отделения №3:
select name from depart
where id*1=3;
id – это первичный ключ, по нему есть индекс. Но при доступе через индекс потребуется минимум два обращения к диску. Включение индексированного поля в выражение (id*1 вместо id) подавляет использование индекса.
5. Используйте UNION ALL вместо UNION, если уверены в том, что в объединяемых отношениях отсутствуют одинаковые записи (или наличие одинаковых записей некритично). Дело в том, что UNION вычисляется путем сортировки, которая может занять много времени.
6. Варьировать использование UNION или OR в зависимости от наличия индекса. Например, список пациентов палат №№3 и 8 при наличии индекса должен быть таким:
select * from patients
where room=3
union all
select * from patients
where room=8;
а если индекса нет, то таким:
select * from patients
where room=3 or room=8;
7. Условие '<>' подавляет использование индекса, поэтому, если значения индексированного столбца распределены неравномерно, следует заменять его на комбинацию '<' or '>' и, с учетом правила (5), реализовывать это с помощью UNION. Например, список сотрудников всех филиалов (10%), кроме центрального офиса:
select * from emp
where deptNo<3
union all
select * from emp
where or deptNo>3;
8. Следует использовать IN вместо EXISTS, если EXISTS не оптимизируется. Например, список пациентов, которые лечатся у хирургов:
select * from patients
where doctor in
(select id from doctors
where special>'A' and special like '%хирург%');
Нельзя забывать, что помимо использования правил написания запросов в настройку приложений входит:
· создание индексов;
· определение потребности в кластеризации и хешировании данных;
· выбор метода оптимизации SQL-запросов;
· использование средств сбора статистики.
При настройке команд SQL важно помнить, что настраивая одну из них можно оказать влияние (и не всегда позитивное) на другие команды. Например, при создании дополнительного индекса могут поменяться планы выполнения всех команд, работающих с этой таблицей.