Д.И.Батищев, С.А.Исаев
Оптимизация многоэкстремальных функций с помощью генетических алгоритмов
(опубликовано в сборнике статей, издаваемом ВГТУ, осень 1997)
Д.И.Батищев, С.А.ИсаевОптимизация многоэкстремальных функций с помощью генетических алгоритмов(опубликовано в сборнике статей, издаваемом ВГТУ, осень 1997) |
|
| . | |
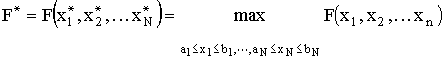
|
ј |
Тестовая задача |
Размерность |
Свойства |
|
1 |
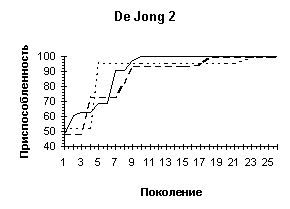
De Jong 2 |
2 |
Овражная функция, один глобальный экстремум |
|
2 |
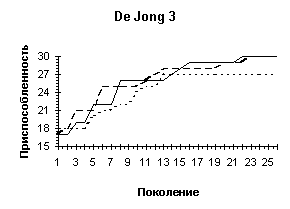
De Jong 3 |
5 |
Разрывы типа "скачек", максимум достигается на гиперкубе |
|
3 |
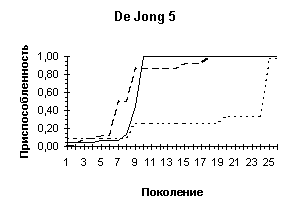
De Jong 5 |
2 |
Один глобальный на гиперкубе, 24 локальных максимума. |
|
4 |
Растригина |
2 |
96 локальных экстремумов и 4 глобальных. |
|
5 |
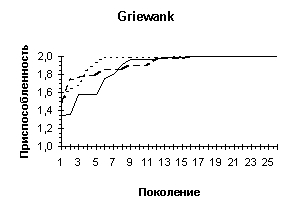
Griewank |
2 |
Один глобальный и множество локальных максимумов. |
|
6 |
Растригина |
10 |
Один глобальный экстремум и 1010- 1 локальных. |
|
7 |
Griewank |
10 |
Один глобальный и множество локальных максимумов |
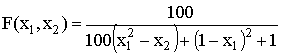 ,
, 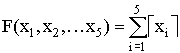 ,
, 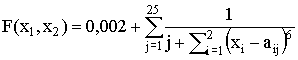 , где a1j = 16[(j mod 5)-2],
a2j = 16[(j % 5)-2],
, где a1j = 16[(j mod 5)-2],
a2j = 16[(j % 5)-2],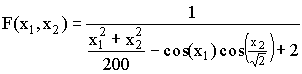 ,
, 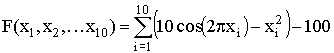 ,
, 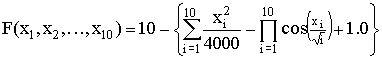 ,
,
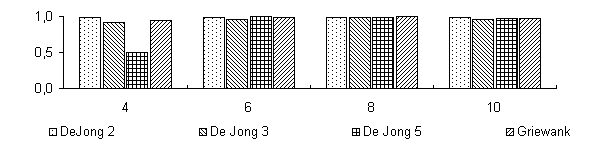
|
|
|
|
|
|
| De Jong 2 (L=4) |
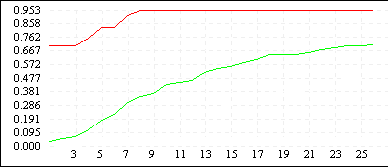 |
| De Jong 2 (L=10) |
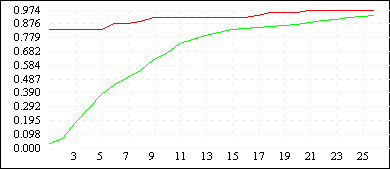 |
| De Jong 5 (L=4) |
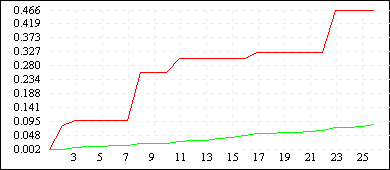 |
| De Jong 5 (L=10) |
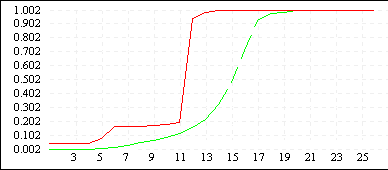 |
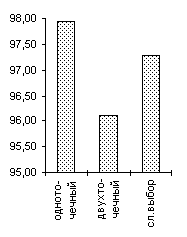
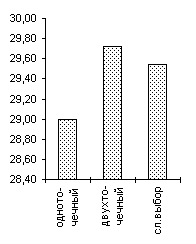
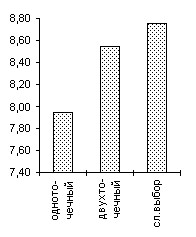
| De Jong 2 |
De Jong 3 |
Griewank (n=10) |
 |
 |
 |
| |
Быстрый поиск |
Описание ландшафта |
Быстрый поиск |
Описание ландшафта |
|
 De |
 Jong 2 |
 De |
 Jong 5 |
||
| |
Быстрый поиск |
Описание Ландшафта |
Быстрый поиск |
Описание ландшафта |
|
| |
 Griewank |
 n=2 |
 Растригин |
 n=2 |
|
| панм-элит |
панм-выт |
селек-элит |
селект-выт |
инбр-элит |
инбр-выт |
аутбр-элит |
аутбр-выт | ||||
| De Jong 2 |
|||||||||||
| Макс |
99,999 |
99,964 |
99,998 |
99,982 |
99,999 |
99,983 |
99,986 |
99,980 | |||
| Мин |
92,254 |
90,735 |
83,529 |
80,211 |
83,725 |
88,445 |
91,754 |
94,843 | |||
| ср.знач |
98,038 |
98,666 |
96,595 |
96,903 |
98,464 |
98,833 |
98,811 |
98,639 | |||
| De Jong 3 |
|||||||||||
| Макс |
29,000 |
29,000 |
30,000 |
30,000 |
28,000 |
29,000 |
30,000 |
30,000 | |||
| Мин |
27,000 |
27,000 |
27,000 |
29,000 |
24,000 |
25,000 |
28,000 |
28,000 | |||
| ср.знач |
28,320 |
28,160 |
29,280 |
29,180 |
26,880 |
27,180 |
28,780 |
28,620 | |||
| De Jong 5 |
|||||||||||
| макс |
1,002 |
1,002 |
1,002 |
1,002 |
1,002 |
1,002 |
1,002 |
1,002 | |||
| мин |
0,502 |
0,550 |
0,202 |
0,966 |
0,202 |
0,715 |
0,988 |
0,910 | |||
| ср.знач |
0,982 |
0,981 |
0,985 |
1,000 |
0,962 |
0,978 |
1,001 |
0,991 | |||
| Griewank n=2 |
|||||||||||
| макс |
1,000 |
1,000 |
1,000 |
1,000 |
1,000 |
1,000 |
1,000 |
1,000 | |||
| мин |
0,836 |
0,871 |
0,871 |
0,871 |
0,871 |
0,869 |
0,872 |
0,906 | |||
| ср.знач |
0,963 |
0,977 |
0,953 |
0,960 |
0,946 |
0,970 |
0,993 |
0,988 | |||
| Растригин n=10 |
|||||||||||
| макс |
-4,989 |
-7,225 |
-8,594 |
-7,982 |
-7,561 |
-11,740 |
-4,937 |
-6,447 | |||
| мин |
-24,932 |
-18,666 |
-25,632 |
-21,839 |
-28,717 |
-30,851 |
-14,996 |
-17,816 | |||
| ср.знач |
-12,077 |
-12,759 |
-14,842 |
-13,671 |
-19,245 |
-20,613 |
-9,432 |
-9,840 | |||
| Griewank n=10 |
|||||||||||
| макс |
9,356 |
9,479 |
9,476 |
9,396 |
9,260 |
9,255 |
9,586 |
9,467 | |||
| мин |
9,027 |
9,034 |
9,051 |
9,078 |
8,708 |
8,445 |
9,069 |
9,069 | |||
| ср.знач |
9,158 |
9,173 |
9,198 |
9,203 |
8,936 |
8,912 |
9,235 |
9,212 | |||
Исаев Сергей
e-mail: mailto:sergey.isaev@mailcity.com
web:
http://www.chat.ru/~saisa/index.html