УДК
004.451.23Информационные технологии, №9, 2002
В.Э. Карпов, И.П. Карпова
Московский Государственный институт электроники и математики
(Технический университет)
Об одной задаче очистки и синхронизации данных
Рассмотрены проблемы согласования данных, полученных из различных источников. Показано, что согласование данных невозможно без предварительной очистки данных. Предложены некоторые формальные методы разбора адресной части данных и очистки этих данных на основе орфо–фонетической унификации, списковой метрики и распознающих автоматов. Приведены результаты применения комбинации этих методов для очистки адресной части данных.
Одной из наиболее актуальных задач организации хранилищ данных является согласование данных, взятых из различных источников. Речь идет прежде всего о совместном использовании разнородных баз данных, не имеющих интерфейса между собой.
Рассмотрим основные проблемы, возникающие при объединении множества баз данных. С технической точки зрения организация крупного банка данных особых трудностей не вызывает – на рынке СУБД можно выбрать подходящий продукт – были бы средства. Однако задача согласования информационных массивов – это крайне дорогое удовольствие.
Согласование данных требуется в том случае, если различные базы данных имеют общие сущности. Эти сущности в разных базах данных могут описываться разными атрибутами и определяются разными первичными ключами. Для согласования данных необходимо выделить атрибуты, которые являются общими для одних и тех же сущностей в разных базах данных и позволяют однозначно идентифицировать экземпляры сущностей. Этот набор атрибутов приводится к общему виду и рассматривается как универсальный первичный ключ (УПК). Он позволяет сопоставлять экземпляры сущностей из различных баз данных.
Основная проблема при создании УПК заключается в том, что согласование данных невозможно без их предварительной очистки. При этом нельзя забывать, что существует принципиальное различие между собственно очисткой данных и проверкой их целостности. Под очисткой следует понимать, во-первых, лексическую верификацию данных, а, во-вторых, их последующую нормализацию (т.е. приведение к одинаковому представлению).
В первом случае речь идет, например, о простейшей проверке типов – содержат ли числовые поля именно числовые данные, насколько корректны указанные даты и т.п. Преобразование дат и времен и приведение их к единому формату, согласования атрибутов полей – все это также относится к лексической верификации. После проведения лексической верификации наступает очередь процедуры нормализации атрибутов. Очистка данных позволяет проводить синхронизацию сегментов информации из различных баз данных и их объединение – там, где это возможно.
Существующие средства очистки условно можно разделить на две категории: универсальные системы, предназначенные для обслуживания всей базы данных, и верификаторы частных атрибутов (например, системы проверки корректности имени, адреса, почтового индекса, телефона и т.п.).
Универсальные системы. На рынке представлены системы в основном этой категории. Это
: Enterprise Integrator компании Apertus; Integrity Data Reengineering Tool производства Validy Technology; Data Quality Administrator от Gladstone Computer Services; Inforefiner фирмы Platinium Technology; QDB Analyze – производство QDB Solutions, Trillium Software System компании Hart-Hanks Data Technologies.Каждая из подобных систем по-своему уникальна и специфична с точки зрения сферы приложения. Например, в продукте фирмы Validy широко используются алгоритмы нечеткой логики, а в Apertus применяются правила, записываемые на специальном языке Object Query Language. Некоторые из этих систем (например Trillium), просматривают данные в поисках определенных образов и обучаются на основе найденной информации. В других образы, подлежащие распознаванию, задаются на этапе предварительного программирования.
Частные верификаторы предназначены для решения менее глобальных задач и обычно ограничиваются очисткой имен и адресов. Пакет компании PostalSoft содержит три библиотеки: исправления и кодировки адресов, оформления правильных имен и слияния/очистки. Первая библиотека корректирует адреса, вторая предлагает способ их стандартизации, третья выполняет т.н. консолидирующие функции. Система Nadis компании Group 1 Software придает адресам вид, отвечающий требованиям почтового ведомства (своего родного, американского). Nadis автоматически преобразует имя и адрес в стандарт Universal Name and Address data standard.
Объединяет подобные системы очистки одно – очень высокая стоимость. Та же Nadis стоит, в зависимости от платформы, от 65 до 250 тыс. долл. Поэтому разработка эффективных и недорогих методов очистки данных является весьма актуальной проблемой.
Рассмотрим далее одну частную задачу синхронизации, являющуюся, тем не менее, весьма распространенной и актуальной не только для организации хранилищ данных, но и для создания менее масштабных, "локальных" систем.
Итак, пусть имеется некоторое множество R баз данных, каждая из которых содержит фрагментарное описание некоторого множества общих объектов X.
Совокупность {R
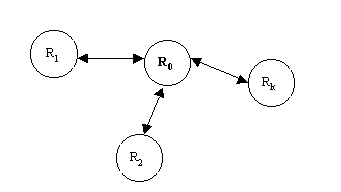
i(X)} является, вообще говоря, множеством логически независимых отношений. Тогда под задачей согласования мы будем понимать создание такой схемы, которая позволила бы установить соответствие между этими отношениями. Обычно для этого строится некоторое базовое отношение R0, играющее роль промежуточного связующего звена (т.н. транзитивное отношение) (рис.1).
Рис.1. Транзитивное отношение
R0 для организации связи между отношениями RiНапример, множество R
i может представлять собой массивы информации о физических или юридических лицах, взятых из различных источников и содержащих свои специфические атрибуты. Тогда для получения "комплексной" выборки требуется умение сопоставить записи в различных Ri между собой. При этом, естественно, предполагается отсутствие единого ключа в Ri, т.к., во-первых, задача при этом теряла бы всякий интерес и смысл, а во-вторых, реально таких ключей почти никогда не существует.Транзитивное отношение R
0 содержит универсальный первичный ключ, состоящий из пересекающегося набора атрибутов, и первичные ключи отношений Ri, позволяя установить соответствие между данными в исходных отношениях Ri. Однако именно определение атрибутов УПК является наиболее трудной задачей.Пусть R
1 – это данные о физических лицах, предоставляемые, скажем, Пенсионным Фондом, R2 – данные, взятые из БД медицинских страховых компаний, а R3 – данные, взятые из БД ГАИ (ГИБДД). Для сопоставления отношений атрибута <Фамилия, Имя, Отчество> явно не достаточно: эта комбинация не является уникальной. Добавление атрибута <Год рождения> также не решает задачи однозначной идентификации. Здесь явно требуется наличие более существенных атрибутов. Одним из наиболее "мощных" атрибутов является адрес (прописки или фактического места жительства). Эти четыре атрибута позволяют почти со стопроцентной вероятностью идентифицировать физическое лицо. Структурная схема данных при такой организации сопоставления приведена на рис. 2.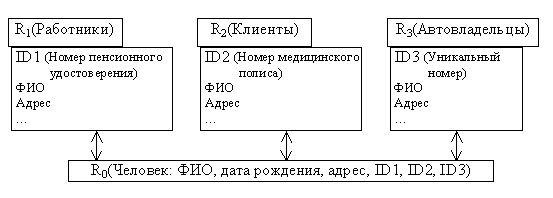
Рис.2. Схема данных, сопоставляемых через транзитивное отношение
R0И вот тут-то оказывается, что именно атрибут <Адрес> является одним из наиболее плохо формализованных. В подавляющем большинстве случаев адресная часть прописывается в одну строку, да еще самым замысловатым, одному только оператору известным образом. А в том ничтожно малом количестве ситуаций, когда адрес представляет собой множество атрибутов <Город>, <Дом>, <Улица>, <Квартира> и др., оказывается, что и улицу давно переименовали, и номер дома перепутан с номером строения и т.д.
Таким образом, разбор адресной части представляет собой важнейший аспект в решении задачи формирования набора ключевых атрибутов для тех предметных областей, в которых фигурирует адрес.
Рассмотрим далее один из способов решения этой задачи.
Разбор адресной части
Итак, пусть имеется неформализованная запись адреса в виде строки символов. Наша задача заключается в разбиении ее на множество атомарных атрибутов. Несмотря на произвол производителей БД, можно считать, что адресная строка обычно имеет следующую структуру: <Индекс>
, <Город>, <Улица>, <Дом>, <Корпус>, <Строение>, <Квартира>. Точнее, так оно должно быть в идеале. Но идеальная структура идеально распознается, а на практике же все выглядит несколько иначе. Отсутствуют некоторые атрибуты, меняется их порядок, добавляются лишние. Иными словами, адресная часть чаще всего оказывается искаженной. Более того, при отсутствии единых общепринятых стандартов и соглашений можно считать, что искажения имеются всегда.Искажения адресной части можно классифицировать следующим образом:
Самая неприятная категория – это синтаксические ошибки. С ними очень сложно бороться. Сложность анализа адресной части во многом определяется необходимостью анализировать контекст, в котором находится распознаваемый атрибут.
Рассмотрим следующий метод разбора адресной части. Будем считать, что адресная строка содержит, справа налево, номер квартиры, строения, корпуса и номера дома. А все остальное, оставшееся слева – это название улицы, город и индекс (если таковые имеются). Это
– так называемый принцип остатка.Разбор адресной части, использующий принцип остатка, состоит из 5 этапов:
Предварительная обработка заключается в переводе строки адреса в один (верхний) регистр и выявлении неинформативных последовательностей символов, например, лишних разделителей. Здесь же происходит и их унификация.
Этап классификации необходим для разнесения множества адресов по территориальным категориям, т.к. синтаксическая корректность адреса зависит от контекста.
Этап лексико-синтаксического анализа состоит в последовательном выделении атомарных атрибутов адреса – названия населенного пункта, улицы, номера дома, корпуса, строения, квартиры.
Постобработка является подготовительным этапом, необходимым для реализации процедуры сопоставления атомарных атрибутов. Суть его сводится к замене нестандартных сокращений на общепринятые варианты, например, "первая" на "1–я", "Нижн." на "Н." и т.д.
Семантический анализ. После выделения атомарных атрибутов следует этап определения корректности семантики адреса. Необходимо определить, имеется ли указанная улица в данном населенном пункте, есть ли такой дом на этой улице и т.д. Определение названия улицы явно сводится к задаче распознавания образов.
Теперь рассмотрим эти этапы подробнее.
Предобработка
Синтаксическому анализатору требуется приведение строки к удобному для анализа и сопоставления виду. Речь здесь идет об удалении лишних разделителей и приведении их к единому виду. Для этого вводится множество правил замены, представленных в виде шаблонов:
" " ® " " ".." ® "." ":" ® " "
";" ® " " ",," ® "," "––" ® "–"
Классификация адреса
Критерием синтаксической
корректности может быть только выявление обязательных адресных составляющих. Например, можно считать адрес разобранным, если удалось выделить номера квартиры и дома (название улицы – это то что осталось). Тогда номер корпуса, строения и индекс – это необязательные атрибуты. Однако это справедливо далеко не для всех адресов. Например, адреса в Зеленограде обычно не содержат номер дома. Вместо них указывается номер корпуса. Свои особенности есть у Новых Черемушек, у адресов воинских частей, у общежитий и т.д. Поэтому прежде, чем заняться синтаксическим анализом, следует определиться с классом адреса, т.е. желательно определить, о каком населенном пункте идет речь.Лексико-синтаксического анализ
Существуют два основных подхода к реализации процедуры выделения составных частей адреса – использование собственно синтаксических методов распознавания (автоматов с магазинной памятью, методов синтаксически управляемого перевода и т.п.), а также метод последовательного применения шаблонов.
Синтаксические методы, к сожалению, плохо применимы на практике. Дело в том, что, во-первых, очень сложно сформировать правила, оставаясь в рамках контекстно-свободных грамматик. А во-вторых, процедура предварительного формирования потока лексем сама по себе трудно разрешима из-за слишком большого множества различных вариантов записи составных частей адресной строки. Большей частью анализ должен опираться на слабоформализуемые, эмпирические соображения.
Поэтому более перспективным представляется следующий подход.
Выделим некоторое упорядоченное множество атомарных атрибутов, составляющих строку адреса. Введем множество шаблонов, которые будем последовательно применять к анализируемой строке. Если очередной шаблон сработал, т.е. удалось выделить из строки атрибуты, то отметим определенные к данному моменту атрибуты для того, чтобы на следующей итерации не применять шаблоны, в которых эти атрибуты присутствуют. Выделение атрибутов приводит к их удалению из строки. Остаток строки вновь анализируется множеством шаблонов. Процедура будет продолжаться до тех пор, пока срабатывают какие-нибудь из шаблонов. Остаток строки будет считаться наименованием улицы.
Пусть в адресной строке находятся следующие атрибуты:
<ГОРОД>,<УЛИЦА>,<ДОМ>,<СТРОЕНИЕ>,<КОРПУС> и <КВАРТИРА>.
При этом, во-первых, некоторые из них могут отсутствовать, а, во–вторых, форма их записи может быть весьма произвольной. Формат описания шаблонов следующий:
<список распознаваемых атрибутов>
% <расположение шаблона 1> <шаблон 1>
% <расположение шаблона 2> <шаблон 2>
…
% <расположение шаблона N> <шаблон N>
<команда>
Расположение шаблона обозначает начало поиска: '*' – искать в любом месте, '[' – искать с начала строки, ']'
– искать от конца строки. В шаблонах применяются следующие метасимволы: 'd' – цифры, 'l' – одна буква, 's' – символы '\' и '/',Тогда шаблон выделения названия населенного пункта может выглядеть так:
ГОРОД
% * "ГОРОД МОСКВА"
% * "ГОР#МОСКВА"
% * "Г@МОСКВА"
% * "Г'МОСКВА"
% [ "ГМОСКВА"
% ] "#ГМОСКВА"
% [ "МОСКВА"
% ] "МОСКВА"
% * " МОСКВА "
= ГОРОД "МОСКВА"
#
Далее можно попытаться выделить номер квартиры (если это записано в почти явном виде – "КВАРТИРА 245", "КВАРТИРА235" или "КВ.16"):
КВАРТИРА
% ] "КВАРТИРА d?"
% ] "КВАРТИРАd?"
% ] "К-РА d?"
% ] "КВ@d?"
% ] "К.d?"
% ] "КВd?"
% ] "КВ/d?"
% ] "Кd?"
% ] "#КОМНАТА d?"
% ] "#КОМ#d?"
= КВАРТИРА "d?"
#
Аналогично выделяются из оставшейся части номер корпуса, строения и дома.
|
КОРПУС |
СТРОЕНИЕ КВАРТИРА |
КОРПУС ДОМ |
ДОМ |
|
% ] "#КОРПУС d?" |
% ] "#СТРОЕНИЕd-d?" |
% ] "#К@d?" |
% ] "#ДОМ d?" |
|
% ] "#КОРПУСd?" |
% ] "#СТРd-d?" |
% ] "#Кd?" |
% ] "#ДОМd?" |
|
% ] "#КОРП@d?" |
= СТРОЕНИЕ "d" |
= КОРПУС "d?" |
% ] "#Д@d?" |
|
% ] "#КОРПd?" |
= КВАРТИРА "d?" |
# |
% ] "#Дd?" |
|
% ] "#КОРd?" |
# |
= ДОМ "d?" |
|
|
= КОРПУС "d?" |
# |
||
|
# |
Сложнее обстоит дело тогда, когда номера пишутся вместе. Например, "...23-А-2-105-В". Шаблон для такого случая может выглядеть так:
ДОМ КОРПУС КВАРТИРА
% ] "#d-l-d-d-l"
= ДОМ "d-l"
= КОРПУС "d"
= КВАРТИРА "d-l"
#
Если же имеется строка вида "...8-8-6-47А", то, видимо, речь идет о доме, корпусе, строении и квартире:
ДОМ КОРПУС СТРОЕНИЕ КВАРТИРА
% ] "#d-d-d-dl"
= ДОМ "d"
= КОРПУС "d"
= СТРОЕНИЕ "d"
= КВАРТИРА "dl"
#
Аналогично определяется и тип улицы – улица, шоссе, проспект и т.п.
|
УПБШ |
УПБШ |
УПБШ |
|
% ] "#УЛИЦА" |
% [ "ПРОСПЕКТ " |
% ] "#БУЛЬВАР" |
|
% [ "УЛИЦА" |
% [ "ПРОСП." |
% [ "БУЛЬВАР " |
|
% ] "#УЛ." |
% [ "ПР-Т#" |
% ] " БУЛЬВ" |
|
% ] "#УЛ/" |
% [ "ПР-КТ#" |
% ] "#Б-ВАР" |
|
% [ "УЛ." |
% ] "#ПРОСПЕКТ" |
% ] "#Б-Р" |
|
% [ "УЛ/" |
% ] "#ПР-Т" |
% [ "Б-ВАР#" |
|
% [ "УЛ " |
% ] "#ПР-КТ" |
% [ "Б-Р " |
|
% * " УЛИЦА " |
= УПБШ "ПРОСПЕКТ" |
% ] "#БУЛ" |
|
% * " УЛ#" |
# |
% [ "БУЛ#" |
|
= УПБШ "УЛИЦА" |
= УПБШ "БУЛЬВАР" |
|
|
# |
# |
Постобработка
Остаток строки, полученный после выделения атомарных атрибутов, также приводится к удобному для анализа и сопоставления виду путем преобразования некоторых фрагментов адресной строки с помощью множества шаблонов замены. Например:
|
* "-АЯ" ® "-Я" |
* "МАЛЫЙ" ® "М." |
|
* "-ОЙ" ® "-Й" |
* "МАЛАЯ" ® "М." |
|
* "-ЫЙ" ® "-Й" |
* "ПЕРВЫЙ" ® "1-Й" |
|
* "БОЛЬШОЙ" ® "Б." |
* "ВТОРОЙ" ® "2-Й" |
|
[ "БОЛ#" ® "Б." |
* "ВТОРАЯ" ® "2-Я" |
|
* "НИЖНЯЯ" ® "НИЖН." |
. . . |
|
* "ВЕРХНЯЯ" ® "ВЕРХН." |
"ВОСЬМАЯ" ® "8-Я" |
После этого строка (точнее, множество выделенных атомарных атрибутов) готова к семантическому анализу.
Семантический анализ
Итак, будем считать, что полученный остаток адресной строки представляет собой название улицы. У нас имеется некоторый словарь-справочник, содержащий официальные имена улиц с указанием, скажем, их кода (объем такого словаря для Москвы составляет около 2.5 тысяч наименований).
Теперь надо сопоставить остаток с содержимым справочника, проверить диапазон номеров домов, квартир и т.п. и получится формально разобранный и проверенный адрес. К сожалению, эта примитивная, казалось бы, процедура оказывается на самом деле не такой простой. Слишком много в реальных данных ошибок, искажений и неточностей. Наибольшее количество ошибок в написании адреса (точнее, в написании названии улиц) приходится, во-первых, на банальные описки или безграмотность, а, во-вторых, на погрешности сканирования (поразительно, как много информации попадает в базы данных непосредственно со сканера, минуя какую бы то ни было фильтрацию).Причем дело даже не в том, что официальное наименование звучит как "ДУБРОВСКАЯ 1–Я", а вместо этого записано "1–Я ДУБРОВСКАЯ" или даже "ПЕРВАЯ ДУБРОВСКАЯ". В конце концов можно перепробовать все варианты перестановки составных частей и воспользоваться к тому же результатами процедур пред- и пост- обработки, превращающих слово "ПЕРВАЯ" в "1–Я". Хуже то, что вместо "ДУБРОВСКАЯ" будет
записано "ДУБОВСКАЯ" или "ДУБР0ВСКАЯ" (цифра "0" вместо буквы "О"). Следовательно, если слово в словаре не найдено, необходимо понять, на какое из имеющихся в словаре имен оно более похоже.Рассмотрим некоторые варианты решения этой задачи.
Явная орфо–фонетическая унификация
Начнем с наиболее простого и распространенного метода распознавания, основанного на вариантах реализации системы Soundex (созданной Германом Холлеритом в конце XIX в. для распознавания имен и применявшейся при переписи населения США в 1890г.)
[1]. Soundex представляет собой один из способов поиска имен по их произношению, решая задачу "фонетической унификации" множества имен.Введенное имя преобразуется следующим образом:
BFVP ® 1, CGJKQSXZ ® 2, DT ® 3, L ® 4, MN ® 5, R ® 6;
Система Soundex основана только на фонетической "близости" различных символов (для английского алфавита, естественно). К сожалению, такой подход не обеспечивает достаточной гибкости и, вообще говоря, чреват серьезными последствиями из–за своего "радикализма". В особенности, когда дело касается фонетически более сложного образования, такого как, например, русский язык.
Поэтому здесь предлагается более "мягкий" вариант орфо-фонетической унификации, учитывающий перечисленные выше искажения.
Например, при сканировании часто цифры 0, 3 и 4 принимаются за буквы О, З и Ч и наоборот. Еще чаше происходят ошибки в правописании, когда путаются "близкие" буквы 'А' и 'О', когда вместо 'Й' пишут 'И' и тем более вместо 'Ё' – 'Е'. Не счесть и двойных согласных, заменяемых на одинарные. Все это можно попробовать учесть с помощью множества шаблонов замены:
* "Ч" ®
"4" * "Й" ® "Е"* "З" ® "3" * "И" ® "Е"
* "О" ® "0" * "А" ® "0"
* "Ь" ® "" * "НН" ® "Н"
* "Ъ" ® "" * "СС" ® "С"
* "'" ®
"" * "ЛЛ" ® "Л"Таким образом, сравнению подлежат не исходные наименования, а результаты орфо–фонетического преобразования названия улицы и элементов словаря.
Списковая метрика
Кроме оценки фонетической близости известны и иные способы определения степени сходства строк (цепочек) символов. Можно определять степень сходства через
Также сравнение цепочек символов может выполняться с помощью определения расстояния между списками, основанного на процедуре перестановки
[3]. При этом сравнение распознаваемого названия улицы Sr с очередным названием Se из общего списка названий улиц производится в два этапа:![]()
где
LE = |Se| – мощность множества Se, КA = |Sr Ç Se| – количество элементов множества Sr, входящих в множество Se, К' = |Sr| – КA – количество элементов Sr, не входящих в Se. Таким образом, учитывается как наличие "лишних" символов, так и отсутствие требуемых, а степень сходства изменяется в пределах [0,1].![]()
и тогда степень сходства d
2 списков можно определить как![]()
где
Ki – количество перестановок (инверсий) в списке Sr`.Окончательная величина степени сходства d анализируемого названия улицы и очередного названия из словаря определяется, например, как произведение d
1 и d 2.Проведя сравнения со всеми названиями улиц, мы можем выбрать то, степень сходства которого будет максимальной. Если же таких названий оказалось несколько, или максимальная степень сходства меньше некоторой пороговой величины, то такие ситуации должны быть разобраны вручную.
Метод распознающих автоматов
Данный метод распознавания конечных последовательностей символов основан на использовании множества вероятностных автоматов
[4], структура которых отражает распознаваемое слово и все возможные варианты его искажения.Процесс распознавания выглядит следующим образом. Для каждого элемента словаря названий улиц строится соответствующий распознающий автомат. Далее распознаваемое слово анализируется последовательно всем множеством автоматов. Результат определяется автоматом, получившим лучший результат распознавания.
Рассмотрим структуру распознающего автомата (рис. 3).
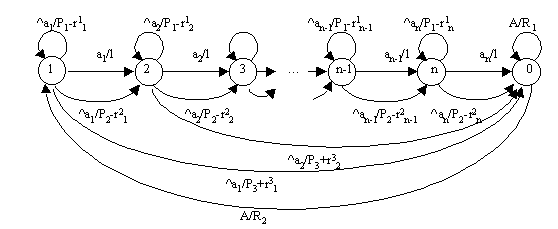
Рис. 3. Структура распознающего автомата
Здесь
n – длина распознаваемого слова, символы которого образуют входной алфавит распознающего автомата A={a1, a2,.., an}.P1, P2, P3, R1, R2 – вероятности шумов при генерации автоматов, а именно:
P1 – петля (лишний символ),
P2 – следующее состояние (искажение),
P3 – конец (нехватка или пропуск символа),
R1 – вероятность остаться в решающем состоянии,
R2 – вероятность возврата в начальное состояние.
При этом необходимо соблюдение следующих условий:
P1 – r1 + P2 – r2 + P3 + r3 = 1,
r1 – r2 – r3 = 0,
r1 = r2 = r3 / 2,
0 £ r3 £ 1 – P3 < 1.
Запись вида '
^ai' означает подачу на вход автомата символа, отличного от ai , а запись вида 'A' – подачу любого символа входного алфавита. В "знаменателе" указана вероятность перехода."Довесок" r изменяется в зависимости от номера состояния i по закону
ri = 1/(n–i+1).
Таким образом, по мере продвижения к конечному состоянию увеличивается вероятность распознавания подаваемого на вход автомата слова.
Настроенный на распознавание конкретного слова автомат воспринимает входную последовательность символов, определяя последовательно вероятность перехода в заключительное (классифицирующее) состояние. Именно значение этой вероятности определяет степень распознавания. На практике порог распознавания устанавливается примерно в 0.3, полагая при этом, что чем длиннее слово, тем пороговое значение должно быть меньше.
Оценить значения вероятностей атрибутов шума можно исходя из различных соображений. В частности, в [5] приведена следующая статистика ошибок наборщиков (в процентах):
Видимо, эта статистика вполне может использоваться и для нашей задачи.
Следует отметить, что система не распознает "близости" входных символов (типа "похожести" звуков "Б"–"П", "В"–"Ф" и т.п.), т.е. не учитывает фонетические особенности реального языка. Однако использование процедуры предварительной орфо–фонетической унификации позволяет успешно справиться с этой проблемой.
Разумеется, помимо рассмотренных выше существует великое множество методов распознавания. Можно говорить и о применении методов инженерии знаний, и о нечеткой логике, и о нейронных сетях.
Наша же задача заключается в том, чтобы предложить достаточно простые формальные методы, которые могут применяться при очистке данных.
Эксперименты по разбору адресной части
Предложенные методы семантического анализа были проверены на реальных данных, адреса в которых не были распознаны путем простого сравнения со словарем.
Для экспериментов использовалась выборка в 1064 записи. Этот подход основывается на известной статистике Колмогорова, из которой следует, что если из массива данных случайно выбирается образец в 1064 элемента, то с достоверностью 99% погрешность оценки распределения данных во всем массиве не превысит полпроцента. При уменьшении мощности образца достоверность оценки уменьшается.
Проверялись следующие методы:
При проведении экспериментов были получены следующие данные (табл.1):
Таблица 1. Результаты экспериментов по очистке данных
|
Метод |
Порог срабатывания |
Предварительная орфо–фонетическая унификация |
Процент распознавания |
|
Орфо–фонетическая унификация |
– |
– |
9.7 |
|
Метод распознающих автоматов |
0.6 |
нет |
4.0 |
|
да |
13.0 |
||
|
0.3 |
нет |
11.4 |
|
|
да |
22.3 |
||
|
0.25 |
нет |
||
|
да |
26.6 |
||
|
Списковая метрика |
0.3 |
нет |
37.5 |
|
да |
51.0 |
||
|
0.6 |
нет |
28.9 |
|
|
да |
45.4 |
Полученные результаты свидетельствуют о том, что если при сопоставлении образца с элементами словаря предварительно преобразовать сравниваемые имена, то можно получить весьма неплохие и достаточно надежные результаты. Процедура предварительной орфо–фонетической унификации улучшает показатели распознавания в 1,5–2 раза. Использование этих методов позволяет автоматически очистить (распознать) от 10 до 45 процентов "грязных" данных.
К сожалению, достоверность распознавания при использовании этих (и любых других) методов очень сложно оценить. Единственным способом более или менее достоверной оценки может быть человек, который просмотрит полученные результаты в виде
{исходная строка адреса} – {распознанное название улицы} и скажет: "Да, я согласен с этими результатами. Ложных срабатываний не произошло". Но реальные данные, например, о жителях Москвы – это миллионы записей, из которых, как показывает практика, от 10 до 30 процентов – это "грязные" данные (т.е. при 8 миллионах записей в среднем от одного до двух миллионов). Просмотреть все эти данные невозможно. Именно поэтому была взята выборка в 1064 записи, которая позволила осуществить выборочный контроль достоверности распознавания. Были определены пороги срабатывания процедур, при котором не происходит (или почти не происходит) ложных срабатываний: 0,25 для распознающих автоматов и 0,6 для списковой метрики.Автоматическая обработка до половины "грязных" данных может считаться хорошим результатом, поэтому, несмотря на простоту, эти методы могут применяться для очистки данных.
Литература
Karpov V.E., Karpova I.P. About one data scrubbing problem
The problems co-ordinate of data set from others sources are considered. Co-ordinate of data is impossible without preliminary data scrubbing. Some formal recognition methods of address data based on phonetic unification, list metric and finite–state automations are proposed. Results of using these methods for address data scrubbing are described.