Информационные технологии, №2, 2002
В.Э. Карпов, И.П. Карпова
Московский Государственный институт электроники и математики
(Технический университет)
К вопросу о принципах классификации систем
Рассмотрены общие проблемы классификации систем. Предложен метод многомерной классификации. Обсуждены перспективы использования этого метода для организации классификаторов в информационно–поисковых системах.
Вплотную заняться проблемой построения классификаций авторам пришлось во время работы в области компьютерных обучающих систем (КОС). Анализ печатных источников позволил сделать вывод о том, что общепринятой классификации КОС не существует. Более того, каждый исследователь приводит и обосновывает свою классификацию, причем все они не свободны от недостатков, что признают и сами авторы. Например, в работе [1] КОС делят на два класса в зависимости от принципов взаимодействия программных обучающих средств и обучаемого
:Жесткой границы между учебными средами и обучающими программами нет. Действительно, системы, обеспечивающие демонстрацию учебного материала, в своем развитии "идут" в направлении учебных сред. А учебные среды-тренажеры в конечном счете сближаются с обучающими программами-тренажерами. Единственное различие, остающееся между обучающими системами этих классов – отсутствие контроля фискального типа в учебных средах и наличие его в обучающих программах.
Другая классификация, приведенная в [2], более обширна. В соответствии с ней компьютерные обучающие средства делятся на:
Несмотря на большее разнообразие, эта классификация также не может претендовать на однозначность. Например, многие компьютерные учебники предоставляют возможность использования лабораторных практикумов и организации контроля знаний, но они будут отнесены к классу "компьютерные учебники" наряду с теми программными продуктами, которые такими возможностями не обладают.
Мы привели далеко не полный список классификаций компьютерных обучающих систем, (см., например, [3–6]), но ни одна из предложенных классификаций не может считаться исчерпывающей.
Несколько лучше обстоит дело с классификациями, используемыми в более "проработанных", "устоявшихся" областях. Однако т.н. эффект пересечения, т.е. неоднозначность классифицирующих признаков, наблюдается и там.
Рассмотрим некоторые классификации аналого-цифровых преобразователей (АЦП) [7, 8]. По виду алгоритма преобразования различают АЦП
Кроме того имеется классификация по способу выбора шкал, в которой АЦП относят к реализующим обобщенный метод считывания и обобщенный метод счета. При этом оказывается, что АЦП, реализующие метод поразрядного кодирования относятся к обоим классифицирующим признакам.
Приведенные выше примеры относятся к категории "плоских" классификаций, в основе которых лежит один классифицирующий признак, например, функциональность, принцип взаимодействия, алгоритм и т.п.. Все подобные классификации не являются однозначными, т.е. строго разграничивающими все пространство объектов.
Кроме "плоских", рассмотренных выше, существуют иерархические классификации [9]. При иерархической классификации все множество объектов разлагается на классы эквивалентности, после чего каждый класс разлагается на классы эквивалентности по другому отношению и т.д.
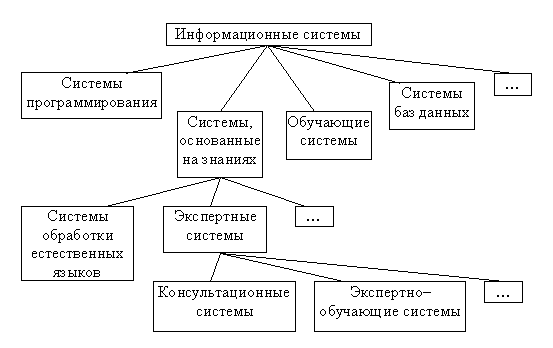
В качестве примера иерархической классификации можно привести классификацию информационных систем в целом. Эта классификация слишком объемна, чтобы в рамках небольшой статьи приводить ее полностью, поэтому на рис. 1 показана только часть этой классификации. Но даже из этого фрагмента видно, что и эта классификация страдает неоднозначностью. Например, правильно ли экспертно–обучающие системы отнесены к классу "Системы, основанные на знаниях"/"Экспертные системы" ? Или было бы логичнее отнести их к обучающим системам ?
Рис. 1. Фрагмент классификации информационных систем
Авторам как–то пришлось наблюдать очень мучительный и поистине титанический процесс классификации. Исследователь пытался создать общую классификацию систем принятия решений. Исчерченный прямоугольниками лист формата А3 никак не мог отобразить непротиворечивую схему, в которой не было бы многочисленных дублирований и циклов. И самым сложным было решение вопроса о том, куда поместить очередной признак и ту или иную конкретную систему. Это – очень показательный пример.
Еще более остро проблема классификации проявляется в системах, связанных с обработкой и упорядочиванием больших информационных массивов. Например, информационных ресурсов Интернет. И здесь ни плоские, ни иерархические классификаторы справиться с задачей упорядочивания не в состоянии.
Некоторым улучшением иерархической классификации является т.н. фасетная классификация. Она отличается от иерархической тем, что на одном и том же множестве объектов строится несколько тематических иерархий. В качестве примера можно привести классификацию систем управления базами данных (СУБД) [10]:
Эта классификация значительно лучше "плоской", т.к. она учитывает более одной характеристики. Но, несмотря на то, что она является общепринятой, в настоящее время она потеряла свою актуальность. Многие современные СУБД обладают как возможностью создания централизованной базы данных, так и функциями распределенности. А используемую в них модель данных с очень большой натяжкой можно назвать реляционной. К тому же эта классификация не учитывает недавно появившиеся объектно-ориентированные СУБД и не содержит других, не менее важных признаков, например, аппаратная и программная независимость, программная совместимость, возможность поддержки хранилищ данных и т.д.
Фактически фасетные классификации представляют собой совокупность нескольких классификаций, каждая из которых определяет принадлежность объекта к определенному классу по одному из признаков объекта. Недостатком подобных классификаций обычно также является неоднозначность определения объектов.
Приведенных примеров достаточно для того, чтобы попробовать разобраться с тем, что такое классификация вообще и как должна выглядеть "хорошая" классификация в частности.
В основе всех видов классификации лежит отношение эквивалентности. При классификации некоторого множества в нем задают одно или несколько отношений эквивалентности и рассматривают классы эквивалентности, связанные с этими отношениями.
Основным критерием корректности построения классифицирующих систем является взаимно-однозначное соответствие между объектом и систематизирующей системой. Т.е. однозначное местоположение объекта в системе (идентификация) с одной стороны и возможность непротиворечивого определения множества свойств искомого – с другой.
Для этого представим все множество классифицируемых объектов в виде точек в некотором конечномерном пространстве признаков.
Координатными осями этого пространства будут независимые классифицирующие признаки. При этом пространство признаков может быть как дискретным (чаще всего классифицирующих признаков немного и они "дискретны"), так и частично непрерывным. В последнем случае речь может идти о некоторых "непрерывных" признаках (например, степень полноты, глубины, удобства и т.п. чего-нибудь).
Введя оси в соответствии с классифицирующими признаками (рис. 2) и определив диапазон или перечень их значений мы получим универсальную классифицирующую систему – многомерный классификатор.
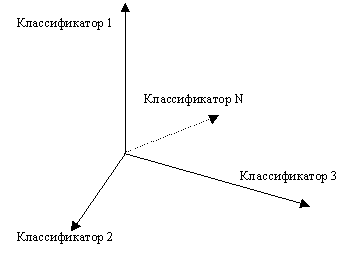
Рис. 2. "Координатные оси" многомерного классификатора
Преимущества использования многомерной классификации очевидны. В частности:
Разумеется, определение набора осей – классифицирующих признаков – является непростой задачей, т.к. необходимо учитывать их "ортогональность". При неудачном выборе существует опасность чрезмерного возрастания размерности пространства. Кроме того, при несоблюдении ортогональности объект может быть представлен не одной точкой, а множеством.
Помимо разрешения сугубо методологических проблем, применение многомерных классификаторов имеет большое практическое значение. Особенно эффективна многомерная классификация для построения информационно–поисковых систем. Об Интернете мы уже упоминали. Рассмотрим теперь еще одну сугубо практическую задачу.
В настоящее на рынке локальных баз данных существует огромное количество информационно–поисковых систем (ИПС). В частности, содержащих справочную информацию о юридических лицах – предприятий, фирм, организаций и т.п. Подавляющее большинство таких ИПС пытается предоставить пользователю информацию о сфере деятельности объекта, его состоянии и т.д. Иными словами – классифицировать. И во всех известных авторам системах для используются единые, в лучшем случае иерархические, а зачастую и просто плоские классификаторы. Анализ классификаторов показывает, что разбиение на классы (разделы) производится не по единому признаку (например, назначение системы или характер деятельности предприятия), а в соответствии со сложившейся практикой. Так, в классификаторе одной базы данных ИПС наряду с разделом "Торговля" существует раздел "Электронный рынок Москвы", а "Строительство и ремонт" выделены в отдельный раздел, хотя в разделе "Услуги (прочее)" есть пункт "Службы ремонта квартир и офисов". Аналогичная картина наблюдается практически на всех поисковых серверах.
Объем этих классификаторов – сотни, даже тысячи признаков (наблюдаемый лично рекорд – 2700 пунктов классификатора в одной из баз данных. Среднее же значение – около полутора тысяч наименований). Многие из признаков перекрывают друг друга, вероятно, с целью предусмотреть возможные комбинации значений этих признаков. Например, признаки "Торговля одеждой и обувью", "Торговля одеждой" и "Торговля обувью". На самом деле это также говорит не только о непроработанности классификации. Дело здесь в принципиальной невозможности построения иерархического классификатора без эффекта пересечения.
Следствием всего этого является трудоемкость поиска информации и отсутствие гарантии нахождения требуемой информации, даже если она есть в базе данных. Все это усложняет язык запросов к данным и делает практически невозможной выполнение нетривиальных запросов.
Представьте себе многочисленные комбинации типа "Продажа–Рыба–Опт", "Производство–Птица–Розница" (не обращая внимания на семантику) и т.п. Даже построив иерархический классификатор мы получим весьма громоздкую и избыточную схему. Не говоря уже о том, каким образом можно будет построить запрос, в котором нас интересуют организации, занимающиеся оптовой продажей рыбы или имеющие хоть какое-нибудь отношение к мясу. Задача эта будет явно неподъемной.
Однако многомерный классификатор разрешает эти проблемы совершенно естественным образом (рис. 3).
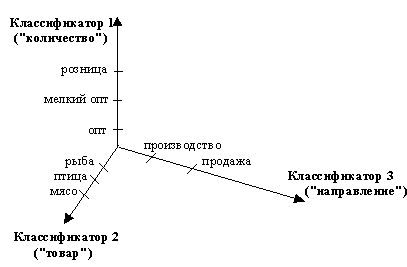
Рис. 3. Пример фрагмента многомерного классификатора
Интересующий нас запрос превратится в нечто вроде
SELECT … WHERE
(количество = опт AND направление = продажа AND товар = рыба)
OR (товар = мясо)
Итак, применение многомерной классификации для систематизации подобного рода информации позволяет уменьшить число позиций – поисковых признаков – в 5–10 раз (применение многомерности позволило снизить упоминавшиеся 2700 позиций всего до 500. Впрочем, это была единичная, разовая работа и потому для оценок эффективности требуется проведение большего количества экспериментов).
Кроме того, применение многомерных классификаторов позволит реализовать сколь угодно сложную выборку на основе построения произвольной функции запроса, реализующей разделяющую поверхность выборки в пространстве признаков.
Литература
Karpov V.E., Karpova I.P. To the Problem about principles of systems classification
General classification problems are considered. A new method based many-dimensional classification is offered. Perspectives of using this method for classifier organization in information retrieval systems are discussed.